How to Determine Which Model to Use in a Data Science Problem

In machine learning, there are a wide variety of models available to the modern practitioner. Everything from the simple linear regression, to extremely complex neural nets. There are models that work for regression problems, and models that work for classification problems. There are models that are extremely fast but not extremely accurate, and models that are extremely accurate, but not at all fast, and many in between. This all begs the question, how do you know which model to use in a given data science problem?
The “Best” Model
Thinking of all of the available tools, one might be tempted to ask, “What is the best model?”. The answer, according to the No Free Lunch Theorems, is that there is no such thing as an overall “best” model. As said by Wolpert and Macready (1995):
“We show that all algorithms that search for an extremum of a cost function perform exactly the same, when averaged over all possible cost functions. In particular, if algorithm A outperforms algorithm B on some cost functions, then loosely speaking there must exist exactly as many other functions where B outperforms A.”
The implication here is that different models work better in different situations, so you need to know your situation in order to know what model to use.
Understanding the Problem

When making this decision, you first must understand your problem. What is the purpose of the model you are creating? How exactly do you plan on using the output of your model? What are the most important aspects of the problem you are trying to tackle? Without the answer to these questions, it will be difficult to determine which model you should choose.
What type of problem are you dealing with?
The first question you need to answer is: Is this a supervised learning problem or an unsupervised learning problem?
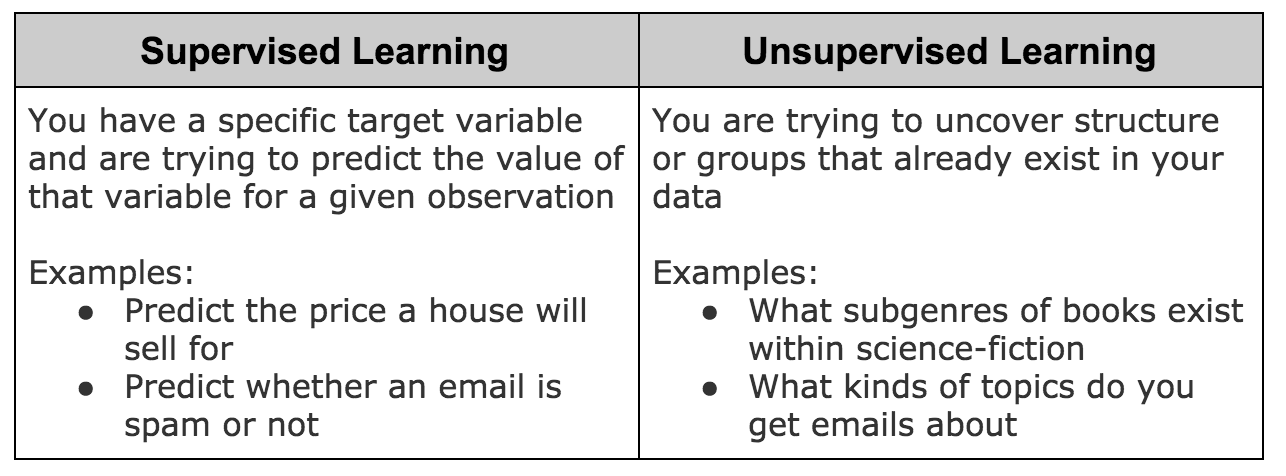
If you’re dealing with an unsupervised learning problem, there are a variety of clustering algorithms you could use to tackle this problem. Rather than explain the various clustering approaches, this post will focus on supervised learning problems instead.
Supervised learning can be further subdivided into regression and classification problems. Regression problems are when you are trying to predict the actual value of a random variable. Classification problems are when you are trying to determine which group or category a given observation is a member of. While there are many algorithms that can be used for both, there are algorithms that are exclusive to one domain or the other.
Is interpretability important?
When you finish creating and running your model, it will give you some kind of output. Are you only interested in the value of the output? Or would you like to understand why and how your model determined the output values? This is the question of interpretability. Some models, like linear regression and logistic regression, are very interpretable. They are relatively easy to understand and explain. Other models, like neural networks, are “black box” models. These models will give you predictions, but you will not be able to tell what specific values or relationships in your data caused those predictions to occur. By knowing the answer to this question ahead of time, you can make sure that your final model will give you what you are looking for
How accurate do you want your model to be?
All models are simplifications of reality. We take an immeasurably complex problem, boil it down to a specific number of variables, and use those variables to create a simplified representation of what is occuring. In some cases, we may just want a model to give us a general idea of the predicted value. For example, if you’re building a model to predict how long your commute will take, you’re probably looking for a general idea rather than an extremely precise value. On the other hand, if you’re working in a high reliability scenario, such as nuclear engineering, you may want your model to be as accurate as you can possibly make it. Once you have this goal in mind, you can then decide when your modeling process has reached a stage you consider complete.
Starting the Modeling Process
1. ALWAYS START SIMPLE!
 |
 |
|---|---|
| Start Here | Don’t Start Here!!!! |
The first rule of selecting a model is to start with the simplest possible model you can. If you can use a simple linear regression that will run extremely quickly to meet your needs, it is unnecessary to bring in abstract and complex models like neural nets and boosting-based models. Additionally, this simple model will give you a baseline to compare against.
Be sure to check if your model performance meets your expectations before moving forward! If you can spin up a simple model with minimal preprocessing that meets your needs, use that model and focus your time on analyzing your results. Models can always improve, but you have to consider if the time and energy that you will spend improving your model are worth the performance gains.
2. Tune Hyperparameters

Once you have fit your first baseline model, you now have something to compare all future models against. From here, you can try adjusting all of the hyperparameters of your model to continue improving it as much as possible. As long as you are seeing gains in your model’s performance, continue tweaking the hyperparameter values! Once you stop seeing performance improvements, or are only seeing marginal improvements, try moving to the next step.
Again, always check to see if your model has met your needs before continuing to work on improving it!
3. Check for Overfit/Underfit
After fitting your first model, you should determine if your model is overfit or underfit. An overfit model will have high variance and low bias, and will generalize to poorly to unseen data. An underfit model will have high bias and low variance, and will perform poorly even on your training data.
If your model is overfit, try the following:
- Adding regularization
- Decreasing your number of features
- Using a simpler model if one exists
If your model is underfit, try the following:
- Increasing your number of features
- Using a more complex model
- Checking if your data holds to the assumptions of your model
4. Try a New Approach
By now, you should have a baseline model set up, and potentially have made some improvements via hyperparameter tuning. You should always try another approach to see if you can get better performance. There’s no need to try every model that you’re familiar with, but never limit yourself to just one approach. You can repeat the above steps for each different model you try.
Not Sure Where to Start?
The table below lists some common models that are easily implementable through scikit-learn in python. Please note that this is not in any way, shape, or form an exhaustive list, but rather a starting point for those unfamiliar with multiple models. Each model name is linked to the appropriate scikit-learn documentation, so feel free to explore in more depth there. Scikit-learn also provides some really awesome tutorials/demos within their documentation, so definitely check it out!
| Model | Use | Interpretable |
|---|---|---|
| Linear Regression | Regression Only | Yes |
| Lasso Regression (L1 penalty) | Regression Only | Yes |
| Ridge Regression (L2 penalty) | Regression Only | Yes |
| Logistic Regression | Binary Classification Only | Yes |
| Naive Bayes | Classification Only | Yes |
| Support Vector Machines (SVMs) | Classification and Regression | No |
| Decision Trees | Classification and Regression | Possibly, depending upon the depth of the tree |
| Ensemble Methods | Classification and Regression | No |
Best of luck with all of your modeling needs!