 <p align="center">Credit to CNN illustrations and Getty Images</p>
<p align="center">Credit to CNN illustrations and Getty Images</p>
On May 17th, 2017 former FBI Director Robert Mueller was appointed by the Justice Department as special counsel to lead the investigation into connections between the 2016 Trump campaign and Russian officials. In the 16 months since then, this investigation has come to dominate the headlines and news cycle. You can find articles and videos about it everywhere.
In addition to the coverage by the media, there is an incredible amount of conversation taking place on social media platforms like Twitter, Facebook, and Reddit. Different sides of the issue have created separate online spaces as bastions of their take on the Mueller investigation. Two such spaces that are diametrically opposed are the subreddits r/The_Donald and r/The_Mueller. Any person reading these two subreddits could easily tell the difference between them, as the sentiment expressed in each is very different, but would a machine be able to do the same?
Problem Statement
The goals of this project are two-fold.
-
Build the most accurate classification model possible for determining what subreddit a post is from
-
Determine the most important predictors in classifying posts by subreddit.
Gathering Data
I gathered my data in two ways for this project.
- Reddit API
- I used the Reddit API to pull down information on approximately 2000 posts from the Reddit servers. (Please note, using the Reddit API requires creating an account and creating a script linked to your account here)
- PRAW
- PRAW (Python Reddit API Wrapper) is a wrapper for the Reddit API that can make it easier to access content through Reddit’s API. While this could be used to accomplish all of the data gathering in this project, I only used PRAW to get the comments for each post.
After gathering my data, I used the pandas package to load it all into a dataframe (think of an excel spreadsheet, but within python) and begin cleaning the data.
Data Cleaning
 <p align="center">This is going to be the cleanest data ever!</p>
<p align="center">This is going to be the cleanest data ever!</p>
After scraping from both subreddits, I had a total of 1,950 posts with the following properties: - 50% from r/The_Donald and 50% from r/The_Mueller - 98 features per post - Multiple categorical and boolean variables.
In order to simplify the data we were working with I took the following steps.
- Drop all features that contained only null values These would obviously not be helpful in categorizing our posts, as they contained no information.
- Drop all features that contained the name of the subreddit except for one. The Reddit api will give multiple pieces of information regarding the subreddit that a post comes from, including the name of the subreddit, the number of subscribers in the subreddit, the type of subreddit, the subreddit id and so on. Since all of these features could quite easily determine where a post came from, I dropped all of them except for the name of the subreddit in order to make sure that I had no information leaking into my modeling data.
- Drop all unnecessary/unrelated feature While it may be important for some to know if the author of a post posted on their cakeday, it was not important to this investigation. Neither was the size of the thumbnail used, or all of the information within the preview of a post. This step involved dropping a large number of features that simply did not relate to the current investigation.
- Investigate remaining features
After eliminating all of the above features, I checked each of the remaining features to make sure they were meaningful and valuable. I found two that I ended up eliminating.
- Author
- There were over 1,000 distinct authors within the collection of posts that I gathered. Since there are fewer than 2000 posts total, the number of authors makes it unlikely that the author of a post will meaningfully predict which subreddit a post came from. It also implies that if my model were to evaluate unseen data, there would likely be many authors that the model has not encountered yet. Therefore, I dropped this feature
- URL
- This feature gives the entire URL that the post links to. This includes self-posts. However, there was another feature
Domainthat gave just the domain name and extension. Since I was most interested in the domain name, I dropped the URL feature
- This feature gives the entire URL that the post links to. This includes self-posts. However, there was another feature
- Author
Now that the data has been cleaned, it is time to jump into some modeling
Modeling
The first model I wanted to use was based on the title and selftext of a post. I engineered a feature by combining the title and selftext into a single string, and then used that string as the only predictor. I attempted to use both count vectorizer and tfidf vectorizer with a multinomial naive bayes classifier and a logistic regression model. The results of which can be seen below.
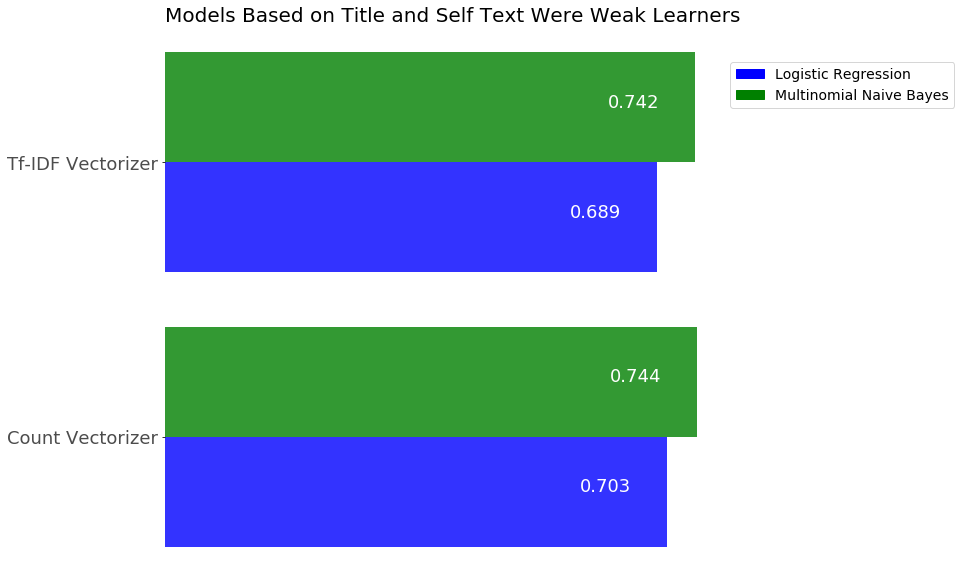 <p align="center">Accuracy scores of first modeling attempts using title and selftext</p>
<p align="center">Accuracy scores of first modeling attempts using title and selftext</p>
While the accuracy results for the testing data from this first set of models were not bad, the models were severely overfit. The accuracy score for each model on the training data was above 95%. After looking at the data more closely, I realized that the average length of each title + selftext string was only approximately 20 words, while the model was using a total of about 5,500 features to make its predictions. Clearly there was just not enough information from each post to determine what the most important features were.
To alleviate this problem, I included all of the numeric metadata with the second model, and added in the flair text and domain variables in the third model. As the number of features grew, the models that I made became more accurate, but for the most part they were still very overfit. The progression in the logistic regression and multinomial naive bayes can be seen in the diagrams below.
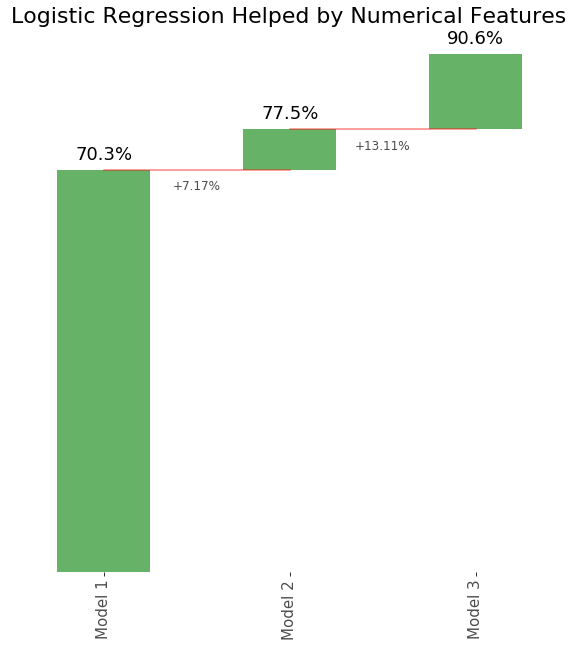 <p align="center">Logistic Regression</p>
<p align="center">Logistic Regression</p>
<p align="center">Multinomial Naive Bayes</p>
The numeric data was very helpful to the logistic regression model, but not as much for the multinomial naive bayes. Same goes for including the flair text. However in creating the third model I ran into a rather difficult challenge. How can I vectorize multiple different text columns? The CountVectorizer and TfidfVectorizer both expect to receive a list-like structure of documents to parse, while I had two separate lists of documents. I ended up manually converting each column, and then combining the resulting matrices with the required variables from the original dataframe. If at this point you’re feeling like this
 <p align="center">What is happening right now?!</p>
<p align="center">What is happening right now?!</p>
trust me when I say that you’re not the only one. This process was confusing and difficult to manage, so I decided to automate it using pipelines.
Custom Pipelines
For those not familiar with pipelines, you can find an introduction here.
When creating my pipelines, my main goal was to only transform the text features of each post, while leaving the other features unchanged. This presented two specific challenges: extracting the desired features to transform and each vectorizer that I wanted to use returned a sparse matrix.
To deal with these challenges, I used two custom classes, SampleExtractor and DenseTransformer. SampleExtractor took in a list of columns and returned that specific slice of my original dataframe, while DenseTransformer took in a sparse matrix and returned a dense matrix. Combining these classes with FeatureUnion and the appropriate vectorizers made my modeling process much simpler than it was previously. Instead of manually transforming my data, the pipeline automatically did so for me. I combined this with gridsearching to optimize the hyperparameters of my models and found that I was able to complete many more models with this new system.
By the end of the modeling process, I had tried using the following models:
- Logistic Regression
- Multinomial Naive Bayes
- Random Forests
- Bagging Classifiers
- Base model = Decision Tree
- Base model = Logistic regression
- Base model = Multinomial Naive Bayes
- AdaBoost Classifier
Evaluating Models
 <p align="center">Which model performed the best?</p>
<p align="center">Which model performed the best?</p>
In evaluating my models, I wanted to keep both of my goals from earlier in mind. I wanted to be able to identify what factors were the best predictors of the post a subreddit came from, and what the most accurate model I could create was. I used a different model to answer each of these questions. The best model I created was an AdaBoost Classifier that used the comments to predict which subreddit a post came from, while the best interpretable model I had was a Logistic Regression model based on the comments.
Most Important features
Comments were by far the most important feature in predicting which subreddit a post came from. This may be because of the sheer amount of information contained within the comments relative to all of the other features in my model; the comments feature included all of the comments in a thread not posted by AutoModerators, while every other feature was much more limited. Some features were missing or blank for many posts, like the selftext.
Because the comments were such strong indicators, I decided to investigate which specific words in the comments were the most predictive.
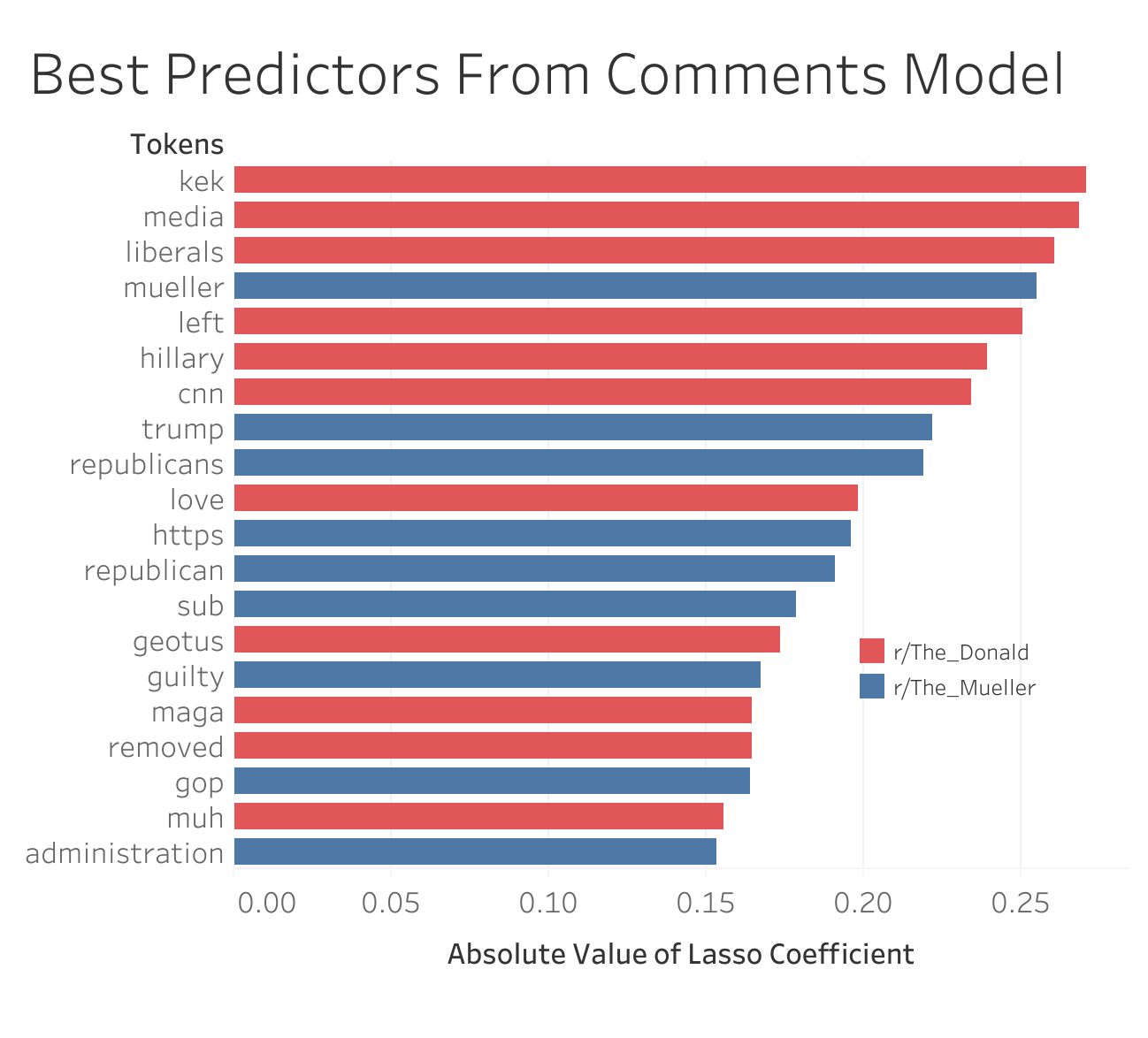 <p align="center">Best predictors based on the Logistic Regression model with vectorized comments as the predictor matrix</p>
<p align="center">Best predictors based on the Logistic Regression model with vectorized comments as the predictor matrix</p>
These were just the top 20 overall predictors. More detailed tables can be found in the full code for this project, posted on my Github.
Most Accurate Models
While the Logistic Regression model I used to generate the above information was very accurate (97.7% accuracy on the testing set), it was not the most accurate model I created. The most accurate model was an AdaBoost Classifier, which had an accuracy of 99.38% on the testing set. While this model does provide feature importances, it fails to include the directionality of those feature importances. So even though the AdaBoost classifier identified “Mueller”, “kek”, “Trump”, “Republican”, and “left” as the five most important features, it failed to describe which subreddit these features were more indicative of.
Interesting Findings
In addition to the findings above, I did notice some other interesting things.
r/The_Donald Loves Exclamation Points!!!!
 <p align="center">!!!!!!!</p>
<p align="center">!!!!!!!</p>
The table above shows a number of features that all predicted a post ended up being in r/The_Donald. The first column is the individual feature, while the “Coefficient” column represents how strong of a predictor the feature was. The closer the value to -1, the stronger the feature predicted that a post belonged to r/The_Donald. Interestingly enough, r/The_Mueller did not have any punctuation based predictors, while r/The_Donald couldn’t get enough of the exclamation point.
Focus on the “Other Team”
In both r/The_Donald and r/The_Mueller, it seemed like the discussion in the comments focused more on those who disagreed with the viewpoint of the subreddit. “Liberals”, “left”, and “Hillary” were all predictors for r/The_Donald, while “Trump”, “republican”, “republicans”, and “administration” were all predictors for r/The_Mueller.
Different Ways of Mentioning the President
Both subreddits consistently referred to the president in different ways. One of the strongest predictors for r/The_Mueller was the presence of the word “Trump”. However, the phrase “President Trump” was among the strongest predictors for r/The_Donald. Commenters in r/The_Mueller were also likely to use “Donnie” when referring to the president.
Next Steps
While I was able to learn a tremendous amount from this project, there are certainly areas for improvement. Three major things I would be interested in continuing to explore are:
1. More Detailed NLP Tools
For this project, I tried using both CountVectorizer and TfidfVectorizer, but there are many more tools available for Natural Language Processing. One thing I would like to try would be stemming or lemmatizing the text features to see how that impacted my models. I would also like to try introducing more stop-words. While I did include common English stop words, I did not include words like “Trump”, “Mueller”, “Investigation”, or any other words that might commonly appear in these subreddits. While none of these words ended up as strong predictors according to the models I developed, it would still be interesting to see how their absence affected the modeling process.
2. Individual Comments vs. Comment Threads
I used entire comment threads as a single feature for my most successful models. Would my modeling process have been as successful if I had used a more limited number of comments? Say I only used the top 10 comments, just the first comment. Or instead of using the entire comment thread as a single feature, what would the impact of using individual comments as individual features be? Could I potentially create a model to predict which subreddit a comment is more likely to come from?
3. Generalizing
My most successful models obviously performed very well within these two specific subreddits. Would this model generalize to similar subreddits? Which subreddits would this model perform best on? Why might it be more successful on those specific subreddits compared to others?
For those interested in more specifics, you can find the code for this project posted on my Github